Text Classification Word Embeddings – Mengenal Lebih Dekat “Word Embeddings”

Text Classification Word Embeddings : Dalam era di mana data semakin menjadi bagian integral dari kehidupan kita, analisis teks menjadi semakin penting dalam memahami dan mengekstrak informasi dari jumlah data yang terus berkembang pesat. Salah satu teknik yang digunakan dalam analisis teks adalah klasifikasi teks, di mana teks diberi label berdasarkan kategori atau topik tertentu. Namun, klasifikasi teks dapat menjadi tugas yang rumit karena teks seringkali berisi kompleksitas dan variasi bahasa yang besar.
Untungnya, ada teknik yang dapat membantu mengatasi tantangan tersebut, yaitu penggunaan “word embeddings” atau representasi vektor kata dalam pemrosesan bahasa alami. Dalam artikel ini, kita akan menjelajahi lebih dalam tentang apa itu word embeddings, bagaimana mereka digunakan dalam klasifikasi teks, dan mengapa mereka begitu penting dalam analisis teks modern.
Apa itu Word Embeddings?
Sebelum kita membahas lebih lanjut tentang bagaimana word embeddings digunakan dalam klasifikasi teks, penting untuk memahami apa sebenarnya yang dimaksud dengan word embeddings. Secara sederhana, word embeddings adalah representasi vektor dari kata-kata dalam ruang multidimensi, di mana kata-kata yang sering muncul bersama memiliki vektor yang lebih dekat satu sama lain dalam ruang tersebut.
Misalnya, dalam representasi word embeddings, kata “rajin” dan “kerja” mungkin memiliki vektor yang lebih dekat satu sama lain daripada kata “rajin” dan “malas”, karena mereka sering muncul bersama dalam konteks yang sama. Dengan kata lain, word embeddings mencoba untuk menangkap makna dan hubungan antar kata-kata dalam sebuah teks.
Bagaimana Word Embeddings Digunakan dalam Klasifikasi Teks?
Salah satu aplikasi utama dari word embeddings adalah dalam klasifikasi teks. Ketika kita memiliki dataset teks yang besar dengan berbagai kategori atau label yang berbeda, kita ingin membuat model yang dapat mempelajari pola dan mengidentifikasi kategori atau label yang tepat untuk setiap teks.
Langkah pertama dalam menggunakan word embeddings untuk klasifikasi teks adalah membangun representasi vektor dari setiap kata dalam dataset kita. Ini biasanya dilakukan dengan menggunakan model bahasa yang telah dilatih sebelumnya, seperti Word2Vec, GloVe, atau BERT, yang memetakan kata-kata ke dalam ruang vektor berdasarkan kemunculan dan konteksnya dalam teks.
Setelah kita memiliki representasi vektor untuk setiap kata dalam dataset, langkah berikutnya adalah menggabungkan vektor kata-kata dalam sebuah teks untuk membentuk representasi vektor untuk teks tersebut secara keseluruhan. Ada beberapa pendekatan untuk melakukan hal ini, seperti mengambil rata-rata vektor kata-kata dalam teks atau menggunakan teknik seperti Doc2Vec untuk memperoleh representasi vektor untuk teks secara langsung.
Sekarang, setelah kita memiliki representasi vektor untuk setiap teks dalam dataset, langkah terakhir adalah melatih model klasifikasi menggunakan representasi vektor tersebut sebagai fitur input. Ini dapat dilakukan dengan menggunakan berbagai model pembelajaran mesin seperti Support Vector Machines (SVM), Naive Bayes, atau algoritma jaringan saraf seperti Convolutional Neural Networks (CNN) atau Recurrent Neural Networks (RNN).
Mengapa Word Embeddings Penting dalam Analisis Teks Modern?
Ada beberapa alasan mengapa word embeddings sangat penting dalam analisis teks modern:
- Merepresentasikan Semantik Kata: Word embeddings membantu dalam merepresentasikan makna kata-kata dalam teks dengan cara yang lebih kaya daripada representasi one-hot encoding tradisional. Ini memungkinkan model untuk memahami konteks dan hubungan antar kata-kata dalam teks.
- Mengatasi Masalah Dimensi: Dalam teks yang panjang dan beragam, jumlah fitur atau kata-kata dapat menjadi sangat besar, yang dapat menyulitkan dalam pelatihan model klasifikasi. Dengan menggunakan word embeddings, kita dapat mengurangi dimensi data dengan menggantikan setiap kata dengan vektor berdimensi lebih rendah, yang memungkinkan model untuk belajar lebih efisien.
- Transfer Learning: Model bahasa yang telah dilatih sebelumnya, seperti Word2Vec atau BERT, dapat digunakan untuk mengekstrak fitur dari teks tanpa perlu melatih model dari awal. Hal ini memungkinkan penggunaan transfer learning, di mana pengetahuan yang diperoleh dari satu tugas dapat digunakan untuk meningkatkan kinerja pada tugas yang berbeda.
- Penanganan Out-of-Vocabulary (OOV) Words: Word embeddings juga dapat membantu dalam menangani kata-kata yang tidak dikenal atau jarang muncul dalam dataset, yang dikenal sebagai Out-of-Vocabulary (OOV) words. Dengan memanfaatkan informasi kontekstual dari kata-kata yang dikenal, model dapat membuat perkiraan yang lebih baik untuk makna kata-kata yang tidak dikenal.
Contoh Soal 1:

Soal 2:

Soal 3:

Soal 4:

Soal 5:

Kesimpulan
Dalam artikel ini, kita telah menjelajahi konsep word embeddings dan bagaimana mereka digunakan dalam klasifikasi teks. Word embeddings memberikan representasi vektor dari kata-kata dalam teks, yang memungkinkan model untuk memahami makna dan hubungan antar kata-kata dalam teks secara lebih baik.
Dengan memanfaatkan word embeddings, kita dapat mengatasi berbagai tantangan dalam analisis teks, termasuk merepresentasikan semantik kata, mengatasi masalah dimensi, menggunakan transfer learning, dan menangani kata-kata yang tidak dikenal. Oleh karena itu, word embeddings menjadi alat yang penting dalam toolbox analisis teks modern dan terus berperan dalam meningkatkan kinerja dan akurasi model klasifikasi teks.
Testimoni jadiBUMN




Program Premium Bimbel jadiBUMN 2024
“Semakin sering latihan soal akan semakin terbiasa, semakin cepat, semakin teliti dan semakin tepat mengerjakan soal-soal Rekrutmen BUMN 2024 ” 
Kunci sukses Tes Rekrutmen BUMN adalah membiasakan diri mengerjakan ribuan tipe soal Tes Rekrutmen BUMN seperti anak bayi yang belajar berjalan terasa berat diawal dan akan terbiasa bila terus dilatih hingga bisa berlari kencang.





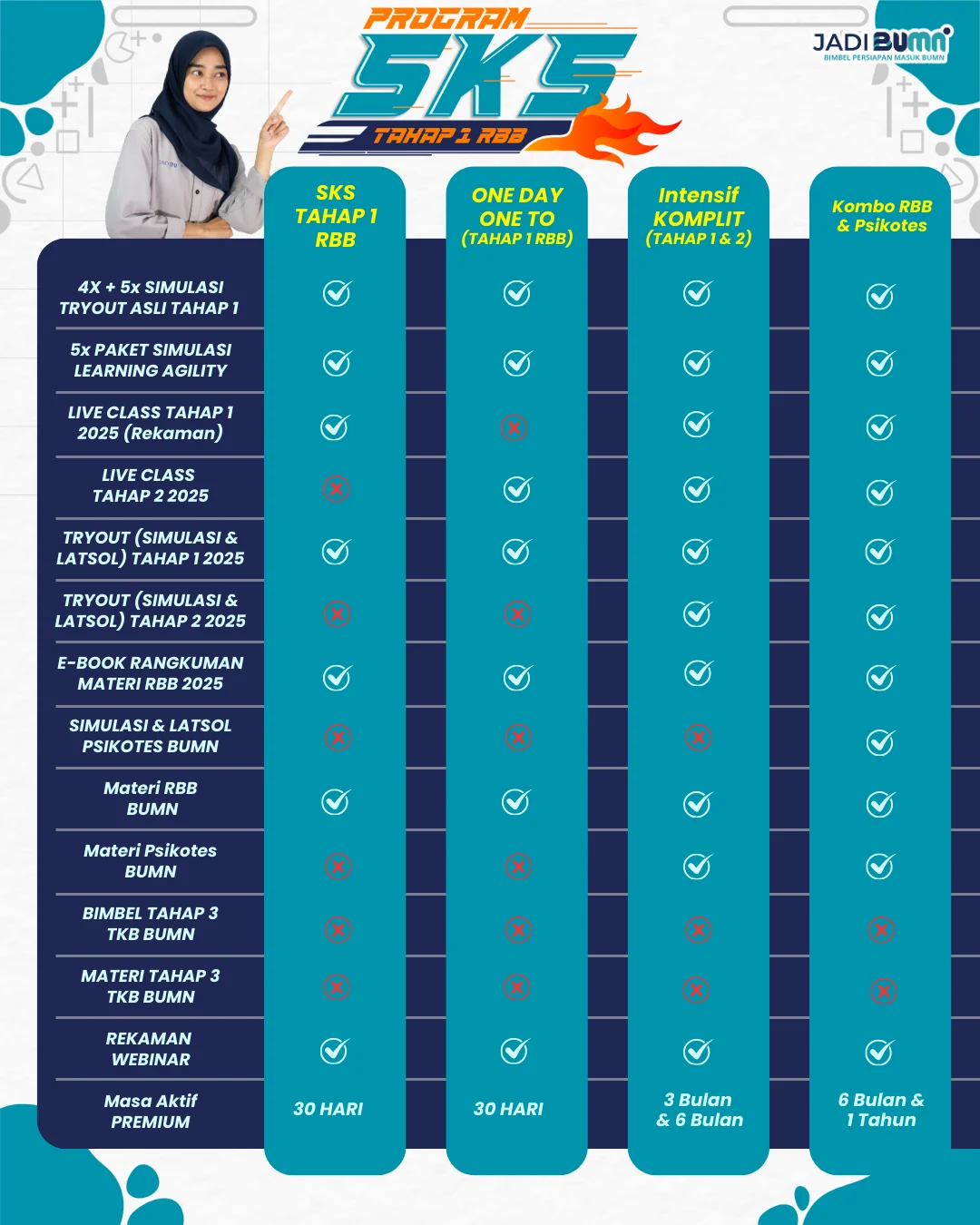


 Cara Membeli dengan Mudah:
Cara Membeli dengan Mudah:
- Unduh Aplikasi jadiBUMN: Temukan aplikasi jadiBUMN di Play Store atau App Store, atau akses langsung melalui website.
- Masuk ke Akun Anda: Login ke akun jadiBUMN Anda melalui aplikasi atau situs web.
- Pilih Paket yang Cocok: Dalam menu “Beli”, pilih paket bimbingan yang sesuai dengan kebutuhan Anda. Pastikan untuk melihat detail setiap paket.
- Gunakan Kode Promo: Masukkan kode “BUMN2024” untuk mendapat diskon spesial sesuai poster promo
- Gunakan Kode Afiliasi: Jika Anda memiliki kode “RES163797”, masukkan untuk diskon tambahan.
- Selesaikan Pembayaran: Pilih metode pembayaran dan selesaikan transaksi dengan aman.
- Aktivasi Cepat: Paket Anda akan aktif dalam waktu singkat setelah pembayaran berhasil.




