

Beyond the Dictionary: Ayo Kulik Word Embedding untuk Klasifikasi Teks di R!
Word Embedding Classification in R – Dunia analisis teks kini semakin canggih. Kita tidak lagi terbatas pada pencarian kata secara literal dalam kamus. Konsep yang disebut word embedding telah muncul sebagai jembatan untuk menghubungkan makna dan hubungan antar kata secara lebih mendalam. Ingin menganalisis teks dengan lebih cerdas dan menguasai klasifikasi teks di bahasa R? Mari kita dalami dunia word embedding dan lihat bagaimana menerapkannya dengan paket populer di R!
Lebih dari Sekedar Definisi: Mengenal Konsep Word Embedding
Pernahkah kamu merasa frustasi ketika mencari arti sebuah kata di kamus? Kamus memang memberikan definisi, tetapi definisi tersebut belum tentu mencerminkan makna kata dalam konteks kalimat yang sesungguhnya. Inilah keunggulan word embedding. Konsep ini tidak hanya berfokus pada definisi kata, melainkan juga menangkap hubungan semantik antar kata berdasarkan penggunaannya dalam kalimat. Dengan demikian, word embedding dapat memahami makna kata secara lebih kontekstual dan menghubungkan kata-kata yang memiliki arti mirip atau berlawanan.
Jenis-jenis Word Embedding: Menjelajah Beragam Pendekatan
Ada beberapa jenis word embedding yang sering digunakan dalam analisis teks. Mari mengenal dua jenis utama:
- Word2Vec: Salah satu metode word embedding yang paling populer. Word2Vec menggunakan jaringan saraf untuk mempelajari hubungan antar kata berdasarkan konteks kemunculannya dalam kalimat. Terdapat dua model utama dalam Word2Vec, yaitu Continuous Bag-of-Words (CBOW) dan Skip-gram. CBOW memprediksi kata berdasarkan kata-kata sekitarnya, sedangkan Skip-gram memprediksi kata-kata sekitar berdasarkan sebuah kata yang spesifik.
- GloVe (Global Vectors for Word Representation): Metode word embedding lain yang berfokus pada statistik kemunculan kata dalam korpus teks besar. GloVe memperhitungkan kemungkinan dua kata muncul bersamaan dalam sebuah konteks untuk menentukan hubungan semantik antar kata.
Klasifikasi Teks dengan Word Embedding di R: Memanfaatkan Paket tidytext
Setelah mengenal konsep word embedding, kini saat menerapkannya untuk klasifikasi teks di R. Paket tidytext dapat menjadi teman kamu dalam proses ini. Paket ini menyediakan berbagai fungsi dan workflow yang membuat analisis teks menjadi lebih mudah dan efisien.
Langkah-langkah Klasifikasi Teks dengan Word Embedding di R:
- Memuatkan Paket dan Data: Langkah pertama adalah memuat paket tidytext dan membaca data teks yang ingin diklasifikasikan. Gunakan fungsi
library(tidytext)untuk memuat paket dan fungsi sesuai dengan format data teksmu untuk membaca data tersebut. - Pembersihan Teks: Sebelum menerapkan word embedding, biasanya diperlukan proses pembersihan teks untuk menghilangkan noise seperti tanda baca, huruf kapital, dan stopwords. Paket tidytext menyediakan fungsi seperti
tolower(),remove_punctuation(), danstop_words()untuk proses pembersihan ini. - Pembuatan Word Embedding: Setelah data teks dibersihkan, langkah selanjutnya adalah membuat word embedding dengan menggunakan metode yang dipilih. Paket tidytext menyediakan fungsi
word_embed()yang dapat digunakan untuk membuat word embedding dengan berbagai metode, termasuk Word2Vec dan GloVe. Kamu perlu menentukan metode word embedding, korpus teks untuk pembuatan word embedding, dan dimensi vector word embedding. - Pembentukan Model Klasifikasi: Setelah word embedding terbuat, kamu dapat membentuk model klasifikasi teks. Paket tidytext menyediakan beberapa fungsi klasifikasi teks, seperti
naive_bayes(),random_forest(), danlogistic_regression(). Pilih model klasifikasi yang sesuai dengan kebutuhan dan data kamu. Gunakan word embedding yang telah dibuat sebagai fitur dalam model klasifikasi. - Evaluasi Model: Langkah terakhir adalah mengevaluasi kinerja model klasifikasi dengan menggunakan metrik seperti akurasi, precision, recall, dan F1-score. Kamu dapat membagi data teks menjadi data latih dan data uji untuk mengevaluasi kinerja model pada data yang belum pernah dilihat sebelumnya.
Contoh Penerapan Klasifikasi Teks dengan Word Embedding di R:
Berikut contoh kode R untuk melakukan klasifikasi teks sentimen film dengan word embedding GloVe:
Cuplikan kode
library(tidytext)
library(tidymodels)
# Membaca data teks
data <- read_csv("data_film.csv")
# Pembersihan teks
data_clean <- data %>%
tolower() %>%
remove_punctuation() %>%
remove_words(stop_words("Indonesia"))
# Pembuatan word embedding
word_embedding <- word_embed(data_clean$review, method = "glove", size = 100)
# Pembentukan model klasifikasi
model <- naive_bayes(sentiment ~ word_embed(review), data = data_clean)
# Evaluasi model
model %>%
model_metrics(data = data_clean)
Gunakan kode dengan hati-hati.content_copy
Tips dan Trik:
- Gunakan korpus teks yang besar dan berkualitas tinggi untuk membuat word embedding yang lebih baik.
- Coba berbagai metode word embedding dan dimensi vector untuk menemukan kombinasi yang paling optimal untuk model klasifikasi kamu.
- Gunakan teknik regularisasi untuk mencegah overfitting pada model klasifikasi.
- Evaluasi model kamu dengan berbagai metrik dan bandingkan dengan model lain untuk melihat kinerja terbaik.
Kesimpulan: Membuka Gerbang Baru dalam Klasifikasi Teks
Word embedding telah menjadi alat yang kuat dalam analisis teks dan membuka peluang baru untuk klasifikasi teks yang lebih akurat dan cerdas. Dengan memahami konsep word embedding dan menerapkannya dengan paket tidytext di R, kamu mampu menganalisis teks dengan lebih mendalam dan membangun model klasifikasi teks yang handal. Dunia analisis teks kini semakin menarik dan penuh potensi untuk dijelajahi!
Contoh Soal Word Classification BUMN
Soal 1
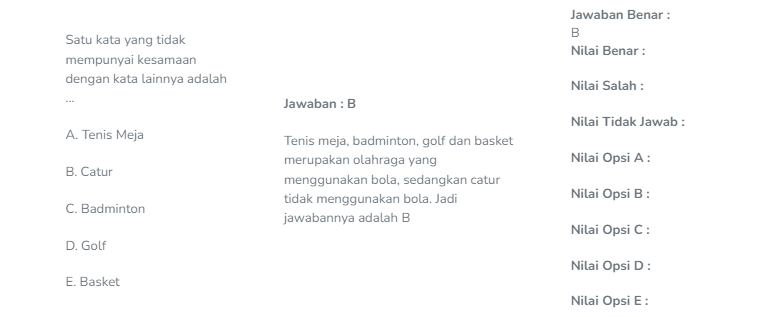
Soal 2

Soal 3
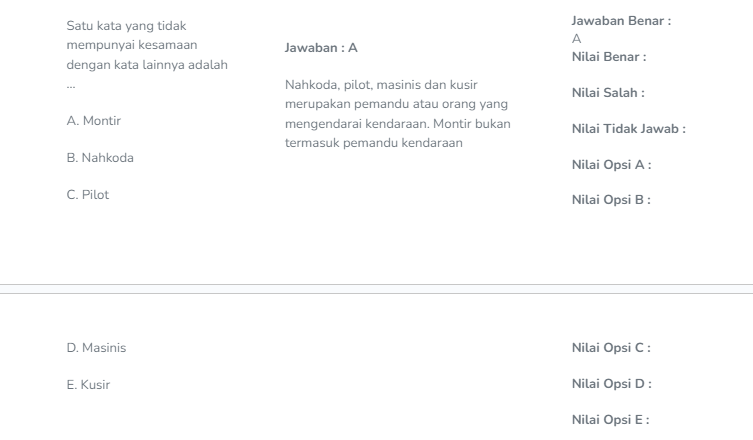
Soal 4

Soal 5

Mau berlatih Soal-soal Rekrutmen BUMN? Ayoo segera gabung sekarang juga!! GRATISSS
Strategi Jitu Menguasai Klasifikasi Kata di Tes BUMN
Soal-soal Klasifikasi Kata di Tes BUMN biasanya disajikan dalam dua bentuk:
- Melengkapi Kalimat: Anda diberi sebuah kalimat dengan satu kata yang hilang. Tugas Anda adalah memilih pilihan kata yang tepat untuk melengkapi kalimat tersebut berdasarkan makna dan fungsinya.
- Menentukan Jenis Kata: Anda diberi sebuah kata dan diminta untuk menentukan jenis katanya (kata benda, kata kerja, dll.).
Berikut strategi jitu untuk menguasai Klasifikasi Kata di Tes BUMN:
1. Pahami Jenis-jenis Kata dan Fungsinya:
Pelajari dengan cermat jenis-jenis kata dan fungsinya dalam kalimat. Pastikan Anda memahami perbedaan antara kata benda, kata kerja, kata sifat, kata bilangan, kata ganti, kata hubung, kata depan, dan kata seru.
2. Perhatikan Konteks Kalimat:
Saat mengerjakan soal Klasifikasi Kata, perhatikan konteks kalimat dengan seksama. Makna kata dapat berubah tergantung pada konteks kalimat di mana kata tersebut digunakan.
3. Gunakan Logika dan Penalaran:
Gunakan logika dan penalaran untuk menentukan jenis kata yang tepat. Pertimbangkan makna kata, fungsi kata dalam kalimat, dan hubungannya dengan kata-kata lain dalam kalimat.
4. Berlatih Soal-soal Klasifikasi Kata:
Semakin banyak Anda berlatih soal-soal Klasifikasi Kata, semakin terbiasa Anda dalam menentukan jenis kata yang tepat. Carilah contoh soal di internet, buku latihan Tes BUMN, atau mengikuti tryout Tes BUMN.
5. Tingkatkan Kosakata Anda:
Memiliki kosakata yang luas akan membantu Anda dalam menentukan jenis kata yang tepat. Bacalah buku, artikel, atau kamus untuk meningkatkan kosakata Anda.
6. Pelajari Struktur Bahasa Indonesia:
Pahami struktur bahasa Indonesia, seperti kalimat aktif dan pasif, kalimat simpleks dan kompleks, serta kalimat majemuk. Pemahaman struktur bahasa membantu Anda dalam menganalisis kalimat dan menentukan jenis kata yang tepat.
7. Bermain Teka-teki Kata:
Bermain teka-teki kata seperti tebak kata atau crossword membantu Anda dalam meningkatkan kemampuan berpikir logis dan memahami hubungan antar kata.
8. Tetap Tenang dan Fokus:
Saat mengerjakan soal Klasifikasi Kata, tetaplah tenang dan fokus. Jangan panik dan terburu-buru dalam menjawab soal. Bacalah soal dengan cermat dan perhatikan instruksinya dengan seksama.
Siap Menjawab Soal Word Classification BUMN 2024?
Menghadapi soal Word Classification BUMN 2024 memang tidak mudah, tetapi dengan strategi yang tepat dan persiapan yang matang, Anda pasti bisa mengatasi tantangan tersebut. Terapkan strategi-strategi yang telah dijelaskan dalam artikel ini, dan jadilah yang terbaik dalam menghadapi tes BUMN. Semoga sukses dalam perjalanan Anda menuju karier di BUMN yang Anda impikan!
Testimoni jadiBUMN




Program Premium Bimbel jadiBUMN 2024
“Semakin sering latihan soal akan semakin terbiasa, semakin cepat, semakin teliti dan semakin tepat mengerjakan soal-soal Rekrutmen BUMN 2024 ” 🌟
Kunci sukses Tes Rekrutmen BUMN adalah membiasakan diri mengerjakan ribuan tipe soal Tes Rekrutmen BUMN seperti anak bayi yang belajar berjalan terasa berat diawal dan akan terbiasa bila terus dilatih hingga bisa berlari kencang.
📋 Cara Membeli dengan Mudah:
- Unduh Aplikasi jadiBUMN: Temukan aplikasi jadiBUMN di Play Store atau App Store, atau akses langsung melalui website.
- Masuk ke Akun Anda: Login ke akun jadiBUMN Anda melalui aplikasi atau situs web.
- Pilih Paket yang Cocok: Dalam menu “Beli”, pilih paket bimbingan yang sesuai dengan kebutuhan Anda. Pastikan untuk melihat detail setiap paket.
- Gunakan Kode Promo: Masukkan kode “BUMN2024” untuk mendapat diskon spesial sesuai poster promo
- Gunakan Kode Afiliasi: Jika Anda memiliki kode “RES163797”, masukkan untuk diskon tambahan.
- Selesaikan Pembayaran: Pilih metode pembayaran dan selesaikan transaksi dengan aman.
- Aktivasi Cepat: Paket Anda akan aktif dalam waktu singkat setelah pembayaran berhasil.
Dan akhirnya, pertanyaan untuk Anda, Apa yang menjadi tantangan terbesar Anda dalam menghadapi soal Word Classification BUMN, dan bagaimana Anda mengatasi tantangan tersebut? Semoga artikel ini membantu Anda dalam mempersiapkan diri dengan lebih baik!







